


Is Peer Review Neutral?
Experimental Evidence

Navigation:
-Introduction
‒Inter-Rater Reliability
‒Schools Of Thought & Confirmation Bias
—A Thought Experiment
—Experimental Evidence
-References
Introduction:
How are we supposed to tell whether peer review successfully filters for quality? One low bar is that if there exists some objective way of telling good from bad, then multiple people should be able to follow some common process that lets them agree on which is which. Of course, it’s completely possible for two people to agree for other reasons, like if they both follow a common rubric with shared flaws, or if both people agree on which conclusions they wish were true or false, but inter-rater reliability (IRR) can at least be regarded as a piece of low-hanging fruit that a journal should pick before figuring out if it has the right reasons for being as high as it is. Take a Pearson correlation coefficient (r) where an r value of z means that a 1-SD increase in x above the mean of x results in a z-SD increase in y above the mean of y; IRR will have a comparable meaning regarding how the ratings of methodological quality produced by one reviewer will reflect those produced by another reviewer, albeit all IRR estimates will be positive. I want you to think, on a pre-hoc basis, about how high you’d want this number to be before you could sleep comfortably at night knowing that it’s at least logistically plausible that peer review filters on the basis of methodological quality.
Inter-Rater Reliability:
In a meta-analysis [49] of studies estimating IRR, the mean estimate for the k = 44 papers using a continuous measure was only 0.34. The authors don’t calculate a proper meta-analytic effect, but in figure 1 they report 95% confidence intervals which allows us to extract these, subtract the lower intervals from the upper intervals, and divide these differences by (2*1.96) to get an estimate of studies’ standard errors for use in a proper meta-analysis:
Extracted using https://plotdigitizer.com

Figure 1. Forest plot of the predicted inter-rater reliability (Bayes estimate) for each study (random effects model without covariates) with 95% confidence interval (as bars) for each reliability coefficient (sorted in ascending order). The 95% confidence interval of the mean value (vertical line) is shaded grey. Predicted values for the same author and year but with different letters (e.g., Herzog 2005a and Herzog 2005b) belong to the same study.
doi:10.1371/journal.pone.0014331.g001
When weighing by squared reciprocal standard errors (i.e. a fixed-effects meta-analytic mean), the effect is a mere 0.2436 (fixed-effects p < 10^-352); this includes an IRR = 0.193, SE = 0.011 effect from the PLOS ONE paper [1]. Moreover, there is enormous publication bias; reliabilities and standard errors correlate at r = +0.599, and when running a mixed-effects meta regression with standard errors as a moderator, the slope is significant at p < 10^-8 and the intercept is only 0.0916 (z = 2.14, p = 0.016). It’s tempting to personify results like these as saying “the mafia investigated the mafia and found no foul play.” In any case, when running a fixed-effects meta-analysis in R using the metafor [48] package and using standard a trim doing a trim & fill correction, the meta-analytic reliability declines from 0.2436 to an estimate of 0.2001 (p < 10^-278). It may however be a bit ridiculous to do this given that it’s not possible to have negative reliability, and we should maybe just go with the reliability of 0.11 that was found in the largest study; this seems conspicuously similar to the intercept of +0.1196 which we get when regressing effect sizes on standard errors, or the 0.0916 intercept we get in the meta regression. Then again, reliability in this context is often literally a correlation coefficient making it technically possible to obtain a below-zero estimate by random chance in the case of a true reliability of zero. In any case, here’s what the funnel plot looks like before and after trim & fill:
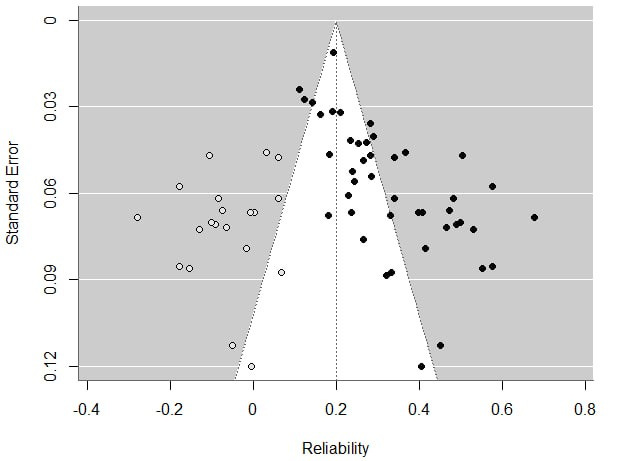
There also exists the IRR value of 0.193 [1] which was later found by a newer examination of 7,981 neuroscience manuscripts submitted for an initial round of review at the journal PLOS ONE. The maximum sample size in the meta-analysis was 1983 [49, p.6] and this paper is singlehandedly 41% of the size of the total N = 19,443 in the meta-analysis, so it may be fair to go with this estimate rather than the largest study in the meta-analysis or with the meta-analytic intercept, in which case this reliability of 0.193 seems like a pretty close to the estimate of 0.2001 which we get when applying a trim & fill correction. Then again, for this examination [1], reviewers were told to evaluate manuscripts purely on their judgements of methodological quality rather than other considerations like whether the journal is appropriate for authors’ papers, meaning that IRR should probably be higher than it would actually be in a natural context.
The thought occurred to me: What if we compared IRR against the standards of reliability we would require for the scales we use anywhere else in quantitative research? The thresholds we follow are completely arbitrary of course, but one [50] pre-hoc judgement from a prominent methodologist reads as follows [50, p.265]:
“In the early stages of predictive or construct validation research, time and energy can be saved using instruments that have only modest reliability, e.g., .70…In contrast to the standards used to compare groups, a reliability of .80 may not be nearly high enough in making decisions about individuals. Group research is often concerned with the size of correlations and with mean differences among experimental treatments, for which a reliability of .80 is adequate…We have noted that the standard error of measurement is almost one-third as large as the overall standard deviation of test scores even when the reliability is .90. If important decisions are made with respect to specific test scores, a reliability of .90 is the bare minimum, and a reliability of .95 should be considered the desirable standard.”
If an IQ test with reliability like this was used to put children in special ed classes, there would be uproar. Frankly, any journal with reliability so low does not have any business being a gatekeeper of anything. Moreover, the meta-analysis [49] also finds that when an objective measure of study quality/transparency (i.e. whether an IRR study reported what kind of IRR it was measuring) is paired with sample sizes, the two moderators explained 86.6% of between-study variance, which was enough for IRR estimates to vary no more than what should be expected from sampling error, thereby implying that there are no exceptions; no journal has any business existing.
Schools Of Thought & Confirmation Bias:
For the few who declared ahead of time that a reliability of ~0.2 should be acceptable, we can now move onto the next question: What other sources of reviewer agreement might exist other than commonly-evident methodological quality shining through? In a meta-analysis of 51 experiments on partisan confirmation bias [13], the combined sample of >18,000 participants judged otherwise-identical information more favorably when they agreed with its conclusions. The was an r = +0.245 effect, equivalent to a moderate Cohen’s d of 0.505 [14, p.21], and the difference in effect size between liberals and conservatives was a non-significant 0.009. Effect sizes (both for overall biases and for conservative-liberal differences) were not moderated by type of information (scientific versus non-scientific) or by sample type (representative versus non-representative), and there was no evidence of publication bias [13].
Is the peer-review system free of such pernicious epistemology? Practicing academics don’t seem to think so when surveyed. In a sample [51] of 361 university professors, most of whom were research methodologists (133 were APA members while 135 were psychometric society members and 93 were members of the American Statistical Association), 76% encountered pressure to conform to the strictly subjective preferences of the reviewers, 73% encountered false criticisms (and 8% made changes in the article to conform to reviewers' comments they knew to be wrong), 67% encountered inferior expertise, 60% encountered concentration upon trivia, 43% encountered treatment by referees as inferior, and 40% encountered careless reading by referees. Given how elite the sample was, the 8% who made changes are also plausibly lower in proportion than what would be found among the general population of publishing researchers.
Academics are only human, and we have good reason to think that they aren’t immune to confirmation bias, and moreover that when they’re selected to be reviewers, they allow it to affect their judgements of methodological quality and of what should get to be published. Generally, they appear to form ‘schools of thought’ that they’re partial towards:
Moreover, there exists evidence suggesting that IQ is more correlated with the ability to come up with reasons for one’s own views than for opposing views [30, pp.83-105; & 31].
In an analysis of 7,981 neuroscience papers [1] submitted for an initial round of review at the journal PLOS ONE, reviewers rated manuscript quality on a 1-4 scale, and their ratings were compared against their distances from the professional networks of the authors whose research they were evaluating (i.e. co-authors of co-authors is an additional degree of separation compared to a relationship where an author and reviewer had directly co-authored a paper together in the past; smallest degrees of separation were used in cases where multiple paths connected authors with reviewers).
Distant and very-distant reviewers (i.e. 2 degrees of separation versus 3+ degrees of separation) were compared in terms of favoritism in order to rule out cynical, careerist effects of neutral citation nepotism and establish validity or their results as measuring the central role of substantive disagreements between scientists in different professional networks (i.e. “schools of thought”). The effect of moving from 1 degree to 2 degrees had the same effect as going from 2 degrees to 3+ degrees, thereby indicating little to no nepotism effect; this is consistent with the evidence [2] I was previously aware of as well as their own literature review [1, p.1830], albeit some heterogeneity in the literature may be explained by higher impact factor journals engaging in greater amounts of nepotism [3]. Under a manuscript fixed-effects design (i.e. single manuscripts judged by multiple reviewers) controlled for reviewer h-indices (i.e. reviewers’ professional prestige) and for the number of different researchers a reviewer had co-authored papers with in the past, each—degree of separation that reviewers had with authors—decreased reviewers’ ratings of the authors’ manuscripts by .107 points on the 1-4 point scale.
Aside from the fixed-effects design, each of the controls had only a modest influence on the strength of the effect, albeit the two have pre-hoc conceptual importance since journal editors apparently assign more-competent reviewers to more-promising manuscripts, and since an editor who has co-authored papers with many people is likely to have less in common with any given one of them.
To me, this design seems sufficiently convincing to accept as revealing the true causal effect. Albeit, special attention should be paid to the units involved. On the scale of quality ratings, 1 codes for rejection, 2 codes for demanding major revisions, 3 codes for demanding minor revisions, and 4 codes for acceptance. Given the standard deviations of the variables involved, the unstandardized beta of .107 corresponds to a correlation of r = +0.078. What’s crucial is that the reliability of both variables is terrible. The inter-rater reliability across reviewers in the first round was only 0.19, and there exists another measure of reviewer distance that the paper compares with its measure of coauthorship distance: Some of the authors nominated which reviewers they wanted to review their papers, and this correlated at only r = -0.274 with coauthorship distance. It’s understandable why coauthorship distance is a requirement for the paper’s design, but if anything, reviewer nomination seems like it should have greater reliability and construct validity as a measure of shared prejudice. As such, it seems fair to at least accept the absolute correlation of 0.274 as a measure of reliability under a model where each measure of coauthorship distance is equally correlated with a latent truescore reliability variable and where 0.274 is the R^2 of how much truescore variance is contained within the coauthorship distance variable. Given these two reliabilities, we can divide 0.78 / √(0.274 * 0.19) = 0.34185546008 to get r = +0.342 as a rough estimate of the causal effect put in correlational terms.
All told, it seems that a reviewer’s ratings of a manuscript will be more correlated with their theoretical prejudices than they will be with the ratings of another reviewer.
Even going with the most optimistic unweighted mean of 0.34 from the meta-analysis, this is actually rounded, with the mean of the effect sizes reported in figure 1 being approximately 0.3387, meaning that the reliability-corrected partiality (r = +0.34185546008) reviewers have towards their school of thought is still a larger effect no matter what.
Granted, this paper [1] only looked at reviewers from PLOS ONE. Are the larger journals any better? Our prior should be that larger journals are equal if not worse on average. Journal rank is positively predictive of retraction rate [53, p.3; & 55, p.3856] and predictive of the incidence of fraud/misconduct/error being the reason for retraction [53, pp.3 & 54]. This correlation with retraction rate shouldn’t solely be attributable to larger journals having a larger readership which does more proofreading, as larger journals are also lower in crystallographic quality [56, p.3], have a higher rate of mislabeled genetic data [56, p.4], have a lower rate of randomization in animal experiments [56, p.4], have an equal amount of statistical power [56, p.4], and have an even probability of blinding in animal experiments [56, p.4]. There’s clear reason to think this is relevant to relative differences in journal bias as well, as larger impact factor journals experience larger declines in effect sizes during replication studies [56, p.4].
Ought editors simply increase the amount of personal distance that reviewers are required to have with authors? Well, there’s a dilemma here between expertise and impartiality. Having expertise in the same research area as an author is necessary for a reviewer to competently evaluate an author’s work, but at the same time, shared expertise comes with reduced personal distance, and with reduced distance, reduced impartiality.
This calls into question the idea that peer review selects for originality. The maximally-original ideas are, by definition, the ones which have the least amount in common which existing research programs, and are hence the ones reviewers are maximally biased against. Moreover, the expertise versus impartiality dilemma is reason to think that reviewers are more disproportionately subscribed to majority opinion than what you’d get from random selection, as the size of a research program determines the amount of personal distance its members can maintain while still being partial towards the same research program. It is always possible to assign an unsympathetic reviewer to members of minority research programs since the smaller the research program, the easier it is to blacklist all members of that research program from being reviewers on the basis that they lack impartiality.
Even if reviewers aren't selected on the basis of orthodoxy, that is, if they are selected at random, it would be true, by definition, that a minority of reviewers will be working on minority research programs. This is fertile ground for the phenomenon [15] of the post-hoc 4th review. It is possible for a member of a minority research program to be assigned sympathetic reviewers by random chance. If an editor doesn’t like their conclusions however, they can simply recruit more and more reviewers until they’re able to find somebody willing to recommend rejection.
A Thought Experiment:
Suppose we had a list of authors C, and two lists of reviewers A & B. Each list is a normal random variable with means of zero and standard deviations of one, and each correlate with the others at r = +0.0. The three lists represent the political views of each category of person, on a single variable of general left versus right political alignment. If we found the differences in political views between A & C, how would these differences correlate with those between B & C? We can actually find the answer analytically using covariance algebra. The answer is r = +0.5.
Premises:
cor(a,c) = 0
cor(b,c) = 0
cor(a,b) = 0
mean(a) = 0
mean(b) = 0
mean(c) = 0
sd(a) = 1
sd(b) = 1
sd(c) = 1
cor(a,c) = cov(a,c)
cor(b,c) = cov(b,c)
cor(a,b) = cov(a,b)
cor(a - c, b - c) = cov(a-c, b-c) / (sd(a-c) * sd(b-c))
cov(a-c, b-c) = cov(a, b-c) - cov(c,b-c)
= cov(a, b) - cov(a,c) - cov(c,b-c)
= cov(a, b) - cov(a,c) - cov(c,b) + cov(c,c)
= cor(a, b) - cor(a,c) - cor(c,b) + cor(c,c)
= 0 - cor(a,c) - cor(c,b) + cor(c,c)
= 0 - 0 - cor(c,b) + cor(c,c)
= 0 - 0 - 0 + cor(c,c)
= 0 - 0 - 0 + 1
= 1
cov(a-c, b-c) = 1
cor(a - c, b - c) = cov(a-c, b-c) / (sd(a-c) * sd(b-c))
cor(a - c, b - c) = 1 / (sd(a-c) * sd(b-c))
sd(a - c) = sqrt(var(a - c))
= sqrt(cov(a, a - c) - cov(c, a - c))
= sqrt(cov(a, a) - cov(a, c) - cov(c, a - c))
= sqrt(cov(a, a) - cov(a, c) - cov(c, a) + cov(c,c))
= sqrt(cor(a, a) - cor(a, c) - cor(c, a) + cor(c,c))
= sqrt(1 - cor(a, c) - cor(c, a) + cor(c,c))
= sqrt(1 - 0 - cor(c, a) + cor(c,c))
= sqrt(1 - 0 - 0 + cor(c,c))
= sqrt(1 - 0 - 0 + 1)
= sqrt(2)
...
sd(b - c) = sqrt(2)
cor(a - c, b - c) = cov(a-c, b-c) / (sd(a-c) * sd(b-c))
cor(a - c, b - c) = 1 / (sd(a-c) * sd(b-c))
cor(a - c, b - c) = 1 / (sqrt(2) * sd(b-c))
cor(a - c, b - c) = 1 / (sqrt(2) * sqrt(2))
cor(a - c, b - c) = 1 / 2
cor(a - c, b - c) = 0.5
Experimental Evidence:
In summary, the kind of people who are chosen to become reviewers (practicing researchers and academics) display confirmation bias when they evaluate evidence, the confirmation bias also applies to how they evaluate methodological quality rather than only what they think is true, expertise has no effect on the magnitude of confirmation bias, and there continues to be confirmation bias when experiments are done with journals’ former reviewers rather than with random academics.
[8] In this experiment, a fake manuscript compared the psychological well-being of a campus cross-section to students who occupied a college administration building, and two forms with flipped results were sent for review to four groups of reviewers from the APA (total N = 322):
An expert group of liberal partisans
A non-expert group of liberal partisans
An expert group of non-liberal partisans
A non-expert group of non-liberal partisans
The results are as follows:

I did my own hypothesis testing with their data (ignoring all ratings except for “How strongly do you recommend the manuscript’s publication?” to avoid multiple testing issues, as this should be the main result), and with all p-values being one-tailed, the results are as follows:
Reviewers gave significantly stronger (d = 0.241, p = 0.015) recommendations when they agreed with the conclusions.
Non-liberals weren’t biased (d = 0.058, p = 0.358) while liberals were (d = 0.329, p < 10^-25); liberals had significantly higher bias, both in terms of having a more significantly-liberal bias (p = 0.0015), and in terms of having a significantly-higher absolute amount of bias in any direction (p = 0.0119).
Specialists and non-specialists did not differ significantly in the strength of their prejudices (p = 0.288). If anything, specialists (d = 0.316, p = 0.0494) were more biased than non-specialists (d = 0.199, p = 0.072) in the point estimate.
[6] This paper did two experiments:
The first experiment recruited 297 science graduate students from The University Of Chicago, 54% of whom were trained in the natural sciences and 54% of whom had training in research methodology. Participants read 20-35 page booklets on two fictitious scientific issues which argued that the case for a hypothesis was either strong or weak, and which were either high quality or low quality; with the addition of a control group, this adds up to subjects being experimentally assigned strong agreement, weak agreement, neutrality, weak disagreement, or strong disagreement. From there, subjects read two research reports, one with conclusions which agreed with their prior views, and one with conclusions which disagreed with their prior views. Effect sizes aren’t given, but subjects rated the reports which agreed with their views as being higher in methodological quality (p < 0.001), and the effects were larger among those assigned stronger views (p < 0.05, Bonferroni corrected).
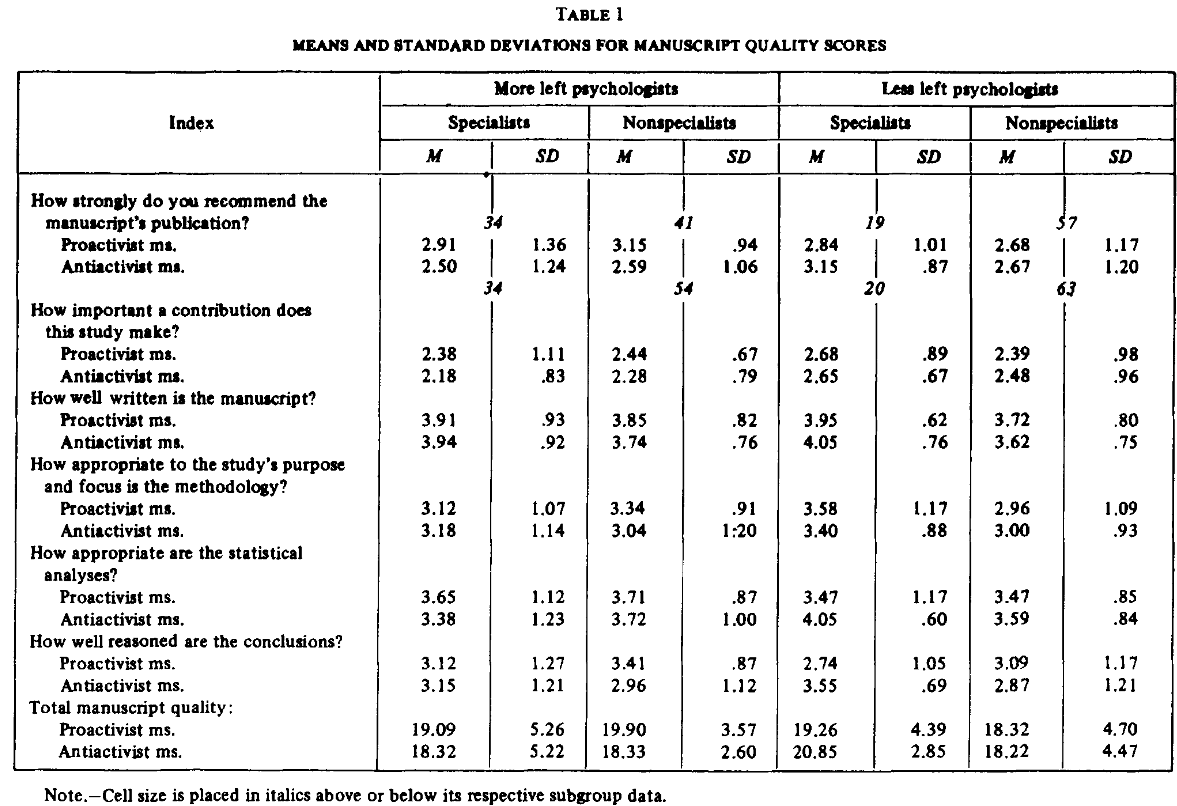
The second experiment recruited 114 active researchers, either skeptical or open to parapsychology, and had them read research reports of either high or low quality which had either positive or negative results. Researchers rated reports to be of significantly (p < 0.01) higher quality when they affirmed their prior views, and this cannot merely be attributed to the parapsychologists being cranks since the effect sizes did not differ significantly (p > 0.05) among groups:


[10] This paper recruited 282 members of the APA and asked them to review one of two abstracts on astrology which were roughly identical aside from their results. One reported significant positive correlations between planetary configurations at the time of birth and one’s subsequent choice of vocation. In general, the participants who received this manuscript rated it at being poorer in design (p < 0.01), having less adequate conclusions (p < 0.05), and being lower in validity (p < .01), except for a subset of astrology believers who rated this version as being significantly (p< 0.01) better designed, more significant for future research (p < .001), and more suitable for publication (p < .001).
[9] This experiment was done with the motivation of being a replication of Goodstein & Brazis’ [10] paper with a much larger (N = 711) sample, with the difference being that they tested for the effects of educational level (Graduate students VS Ph.Ds VS professors VS associate professors VS assistant professors) and also tested the astrology manuscripts against ones testing the effects of measured (NEO-PI-R) personality on real-world behavior. In all, participants were sent one of twelve possible fictional abstracts: 1/3rd of these were high-quality analyses, 1/3rd medium quality analyses, 1/3 were low-quality analyses, 1/2 had positive results, 1/2 had negative results, 1/2 were about astrology, and 1/2 were about personality. Only 14 participants reported believing in astrology, so they were simply excluded rather than doing an underpowered analysis of whether their biases differed significantly. The results were as follows:
Although participants with higher levels of educational attainment rated all twelve abstracts as significantly lower in quality than did other participants, they did not differ significantly in their bias towards preferred conclusions. The authors cite two previous papers [12 & 84] as their reason for thinking expertise would have an effect on confirmation bias, and while I can only access their abstracts, the former has a total sample of only 32 subjects and is hence significantly underpowered (especially considering the need for random manuscript assignemnt) while the latter does not test its two groups for differences in confirmation bias. As such, the best existing evidence [8 & 9] can be taken as finding no effect of expertise on confirmation bias.
Topic (astrology versus personality) and conclusion (positive and negative) had a significant interaction effect on how participants rated the methodological quality of the abstracts.
They only report whether p values are under 0.05 rather than testing whether they fall below any other thresholds, but for the Topic X Conclusion interaction effect, F(1, 625) = 37.05, η^2 = 0.056, and we can calculate for ourselves that the p-value is under 0.00000001; this partial η^2 value is the equivalent of a value of 0.24 for Cohen’s ƒ, which is the equivalent of a value of 0.48 for Cohen’s d [11]. Astrology abstracts with null results were rated as significantly (F(1,705) = 55.40, p < 0.000000000001) higher in methodological quality than personality abstracts with null results, and astrology abstracts with positive results were rated as significantly (F(1,705) = 11.46, p < 0.001) lower in methodological quality than personality abstracts with positive results. Finally, astrology abstracts with null results were rated as significantly higher in methodological quality than otherwise-identical ones with null results (F(1,705) = 48.28, p < 0.00000000001) whereas personality abstracts with null results were rated as significantly lower in methodological quality than ones with null results (F(1,705) = 15.13, p < 0.0001):
Fig. 1 Interaction between topic (astrology theory, personality theory) and conclusion (confirmation, disconfirmation) on perceived quality of the abstracts
[7] The editor for The Journal of Social Behavior and Personality agreed to an experiment where 53 of the journal’s reviewers were surveyed on their views regarding the effect of—maternal availability during childhood—on personality in adulthood (a rather milquetoast topic on which the reviewers nevertheless managed to have vitriolic political opinions) before being assigned one of two versions of a manuscript:
The first version placed emphasis on the significant associations found on certain outcomes.
The second version placed emphasis on the lack of significant associations found on other outcomes.
Reviewers with a positive orientation toward nonmaternal care were more likely to recommend Version 1 of the manuscript for publication while reviewers with a negative view of nonmaternal care were more likely to recommend Version 2 of the manuscript for publication.
The fact that the editor here was open to the experiment at all is evidence that this journal is probably better than average in terms of being ideologically unbiased. The bias of reviewers alone is enough to ensure that the scientific literature is distorted on the basis of what conclusions they want to be true. Getting editors involved in covertly pushing an agenda will only *exacerbate* political biases rather than creating them. Writing guidelines against accepting certain conclusions in a journal's editorial ethics standards will in all likelihood merely formalize what was already established practice.[52] In this experiment, 238 reviewers from The Journal of Bone and Joint Surgery and from Clinical Orthopaedics and Related Research were solicited to review one of two randomly assigned manuscripts concerning the efficacy of a form of joint surgery in a well-designed RCT which were otherwise identical aside from one version finding positive results and the other finding null results. Reviewers who received the version with positive results were significantly (p < 0.001) more likely (97.3% vs 80.0%) to recommend the manuscript for publication, which isn’t too interesting since on its own, this result could be written off as the positive version being more interesting and hence more publishable even were the methodological ratings to be identical. However, reviewers also gave higher methodological ratings (8.24 vs 7.53, P < 0.01) to the version of the manuscript with positive results. Moreover, there were 7 intentionally-planted errors in both versions of the paper; in the version of the manuscript with positive results, reviewers found an average of 0.41 errors whereas reviewers found a significantly-higher (p < 0.001) average of 0.85 errors in the version with null results. It’s concerning enough how few errors reviewers catch even under conditions of motivated reasoning, but more importantly, this is useful in that:
This is the largest paper generalizing evaluative double standards to actual reviewers rather than to random academics or to university students.
This illustrates how even with neutral journal guidelines (which as we’ll see, can’t always be assumed) based purely on methodological quality, a research literature can be skewed merely by varying the leniency with which papers are evaluated. If this wasn’t an experimental comparison, the reviewers could easily defend their decisions on the basis that there were higher numbers of objective flaws found in the paper they gave lower ratings to.
[5] In this experiment, 75 reviewers from The Journal Of Applied Behavioral Analysis were solicited to review a fictional manuscript examining the effects of extrinsic reinforcement on intrinsic interest, a controversial topic in psychology on which the journal had adopted the hard-line stance that extrinsic reinforcement acts to enhance intrinsic interest. Reviewers were asked to rate the relevance, methodology, data presentation, discussion, scientific contribution, and overall recommendations regarding the manuscript, which had been experimentally manipulated to yield positive results, negative results, no results, mixed results portrayed as supporting the journal’s view, and mixed results portrayed as supporting the journal’s view. The experiment really doesn’t have the statistical power to adjust for the excessive multiple testing problems, so the responsible thing is to only mention what should’ve been their main result: The reviewers who were sent manuscripts with negative results had d = -0.84, p = 0.0136 significantly lower overall evaluations. While it’s nice to have more confirmation, this isn’t too interesting, as:
This isn’t distinguishable from regular publication bias since their perspective was framed as being consistent with a positive result rather than being consistent with a negative result.
The journal reviewers were only compared against themselves across experimental conditions, rather than there being other reviewers with a different perspective from a different journal who could be demonstrated as yielding oppositely-biasing effects.
This stated, manuscripts with negative results also arguably had d = -0.779 lower methodology ratings with a one-tailed test (t = 2.06, p = 0.0197) surviving two-test Bonferroni correction, thereby suggesting that it isn’t a matter of equally-rated papers merely being rated as more interesting/relevant in cases where they have positive results. In any case, what’s more interesting than their experimental results is that reviewers’ ratings on the quality of ‘data presentation’ correlated at r = +0.6 with their ratings on methodological quality, which implies a halo effect where if they have some prejudiced idea of an article as being good, then they’ll globally judge all aspects of it as being good rather than evaluating each aspect of it independently.
Although the sample is pretty small, this effect size is large enough that it’s significant at p < 10^-20. There should exist 99% power to detect a one-tailed effect at p<0.001 at only n=64. If we also think of each aspect of manuscript quality as merely being indicators of an underlying latent ‘prejudice’ factor which correlates evenly with each indicator, this r = +0.6 might properly be thought of as 60% of the *variance* in each indicator being explained by the prejudice factor.
This isn’t just a matter of competent authors producing higher-quality manuscripts in every aspect, as the same manuscript was shown to all reviewers and this should thus be controlled for. This also isn’t a matter of us lacking proper context due to most variance in manuscript ratings being between manuscripts, as we already know that the inter-rater reliability of reviewers is consistently found to be terrible.

References:
Teplitskiy, M., Acuna, D., Elamrani-Raoult, A., Kording, K., & Evans, J. (2018). The Social Structure of Consensus in Scientific Review. Research Policy, 47(9). Retrieved from http://not-equal.org/content/pdf/misc/10.1016-j.respol.2018.06.014.pdf
Sugimoto, C. R., & Cronin, B. (2013). Citation gamesmanship: Testing for evidence of ego bias in peer review. Scientometrics, 95, 851-862. Retrieved from https://sci-hub.ru/https://doi.org/10.1007/s11192-012-0845-z
Wilhite, A. W., & Fong, E. A. (2012). Coercive citation in academic publishing. Science, 335(6068), 542-543. Retrieved from https://sci-hub.ru/https:/doi.org/10.1126/science.1212540
Ceci, S. J., Peters, D., & Plotkin, J. (1985). Human subjects review, personal values, and the regulation of social science research. American Psychologist, 40(9), 994. Retrieved from https://not-equal.org/content/pdf/misc/Ceci1985.pdf
Mahoney, M. J. (1977). Publication prejudices: An experimental study of confirmatory bias in the peer review system. Cognitive Therapy and Research, 1(2), 161–175. Retrieved from https://sci-hub.ru/https:/doi.org/10.1007/BF01173636
Koehler, J. J. (1993). The Influence of Prior Beliefs on Scientific Judgments of Evidence Quality. Organizational Behavior and Human Decision Processes, 56(1), 28–55. Retrieved from https://sci-hub.ru/https://doi.org/10.1006/obhd.1993.1044
Hojat, M., Gonnella, J. S., & Caelleigh, A. S. (2003). Impartial Judgement by the “Gatekeepers” of Science: Fallibility and Accountability in the Peer Review Process. Advances in Health Sciences Education, 8(1), 75–96. Retrieved from https://sci-hub.ru/https://doi.org/10.1023/A:1022670432373
Abramowitz, S. I., Gomes, B., & Abramowitz, C. V. (1975). Publish or Politic: Referee Bias in Manuscript Review. Journal of Applied Social Psychology, 5(3), 187–200. Retrieved from https://sci-hub.ru/https://doi.org/10.1111/j.1559-1816.1975.tb00675.x
Hergovich, A., Schott, R., & Burger, C. (2010). Biased Evaluation of Abstracts Depending on Topic and Conclusion: Further Evidence of a Confirmation Bias Within Scientific Psychology. Current Psychology, 29(3), 188–209. Retrieved from https://sci-hub.ru/https:/doi.org/10.1007/s12144-010-9087-5
Goodstein, L. & Brazis, K. (1970). Credibility of psychologists: An empirical study. Psychological Reports, 27(3), 815-838. Retrieved from https://sci-hub.ru/https://doi.org/10.2466/pr0.1970.27.3.835
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.), Hillsdale, NJ: Erlbaum. Retrieved from https://not-equal.org/content/pdf/misc/Cohen1988.pdf
Krems, J. F., & Zierer, C. (1994). Sind Experten gegen kognitive Täuschungen gefeit? Zur Abhängigkeit des confirmation bias von Fachwissen. [Are experts immune to cognitive bias? The dependence of confirmation bias on specialist knowledge]. Zeitschrift für experimentelle und angewandte Psychologie, 41(1). Retrieved from https://psycnet.apa.org/record/1994-87315-001
Ditto, P. H., Liu, B. S., Clark, C. J., Wojcik, S. P., Chen, E. E., Grady, R. H., … Zinger, J. F. (2018). At Least Bias Is Bipartisan: A Meta-Analytic Comparison of Partisan Bias in Liberals and Conservatives. Perspectives on Psychological Science, 14(2). Retrieved from https://sci-hub.ru/https://doi.org/10.1177/1745691617746796
Ruscio, J. (2008). A probability-based measure of effect size: Robustness to base rates and other factors. Psychological Methods, 13(1), 19-30. Retrieved from https://sci-hub.ru/https:/doi.org/10.1037/1082-989x.13.1.19
Fuerst, G. R. (2021). The Post-hoc 4th Review. Human Varieties. Retrieved from https://humanvarieties.org/2021/10/21/the-post-hoc-4th-review/
Langbert, M. (2018). Homogenous: The Political Affiliations of Elite Liberal Arts College Faculty. Academic Questions, 31(2), 186–197. Retrieved from https://sci-hub.se/https://doi.org/10.1007/s12129-018-9700-x
Lipset, S. M., & Ladd,, E. C. (1972). The Politics of American Sociologists. American Journal of Sociology, 78(1), 67–104. Retrieved from https://sci-hub.ru/https:/doi.org/10.1086/225296
Hamilton, R. F., & Hargens, L. L. (1993). The politics of the professors: self-identifications, 1969–1984. Social Forces, 71(3), 603-627. Retrieved from https://sci-hub.ru/https://doi.org/10.1093/sf/71.3.603
Klein, D. B., & Stern, C. (2009). By the numbers: the ideological profile of professors. The politically correct university, 15-37. Retrieved from https://www.aei.org/wp-content/uploads/2014/07/-politically-correct-university_100224248924.pdf
Gross, N., & Simmons, S. (2007, October). The social and political views of American professors. In Working Paper presented at a Harvard University Symposium on Professors and Their Politics (p. 41). Retrieved from https://studentsforacademicfreedom.org/wp-content/uploads/2020/05/lounsbery_9-25.pdf
Onraet, E., Van Hiel, A., Dhont, K., Hodson, G., Schittekatte, M., & De Pauw, S. (2015). The Association of Cognitive Ability with Right-wing Ideological Attitudes and Prejudice: A Meta-analytic Review. European Journal of Personality, 29(6), 599–621. Retrieved from https://sci-hub.ru/https://doi.org/10.1002/per.2027
Strenze, T. (2007). Intelligence and socioeconomic success: A meta-analytic review of longitudinal research. Intelligence, 35(5), 401–426. Retrieved from https://sci-hub.ru/https://doi.org/10.1016/j.intell.2006.09.004
Uttl, B., Violo, V., & Gibson, L. (2024). Meta-analysis: On average, undergraduate students' intelligence is merely average. ScienceOpen Preprints. Retrieved from https://www.scienceopen.com/hosted-document?doi=10.14293/S2199-1006.1.SOR.2024.0002.v1
Angleson, C. (2022). Learning, Memory, Knowledge, & Intelligence. half-baked thoughts. Retrieved from https://werkat.substack.com/p/learning-memory-knowledge-and-intelligence-14a
Dey, E. L. (1997). Undergraduate political attitudes: Peer influence in changing social contexts. The Journal of Higher Education, 68(4), 398-413. Retrieved from https://sci-hub.ru/https://doi.org/10.1080/00221546.1997.11778990
Strother, L., Piston, S., Golberstein, E., Gollust, S. E., & Eisenberg, D. (2020). College roommates have a modest but significant influence on each other’s political ideology. Proceedings of the National Academy of Sciences, 202015514. Retrieved from https://sci-hub.ru/https://doi.org/10.1073/pnas.2015514117
Pasek J., Tahk, A., Culter, G., & Schwemmle. M. (2021). weights: Weighting and Weighted Statistics. R package version 1.0.4,. Retrieved from https://cran.r-project.org/package=weights
Carl, N. (2015). Can intelligence explain the overrepresentation of liberals and leftists in American academia? Intelligence, 53, 181–193. Retrieved from https://sci-hub.ru/https://doi.org/10.1016/j.intell.2015.10.008
Kaufmann, E. (2021). Academic freedom in crisis: Punishment, political discrimination, and self-censorship. Center for the Study of Partisanship and Ideology, 2, 1-195. Retrieved from https://cspicenter.org/wp-content/uploads/2021/03/AcademicFreedom.pdf
Perkins, D. N., Farady, M., & Bushey, B. (1991). Everyday reasoning and the roots of intelligence. In D.N. Perkins, M. Farady, & B. Bushey (Eds.), Informal reasoning and education. (pp. 83-105). Hillsdale, NJ: Erlbaum. Retrieved from http://not-equal.org/content/pdf/misc/Perkins1991.pdf
Perkins, D. N. (1985). Postprimary education has little impact on informal reasoning. Journal of Educational Psychology, 77(5), 562–571. Retrieved from https://sci-hub.ru/https://doi.org/10.1037/0022-0663.77.5.562
Dürlinger, F., & Pietschnig, J. (2022). Meta-analyzing intelligence and religiosity associations: Evidence from the multiverse. Plos one, 17(2), e0262699. Retrieved from https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8836311/pdf/pone.0262699.pdf
Zuckerman, M., Silberman, J., & Hall, J. A. (2013). The Relation Between Intelligence and Religiosity. Personality and Social Psychology Review, 17(4), 325–354. Retrieved from https://sci-hub.ru/https://doi.org/10.1177/1088868313497266
Jeynes, W. H. (2004). Comparing the Influence of Religion on Education in the United States and Overseas: A Meta-Analysis. Religion & Education, 31(2), 83–97. Retrieved from https://sci-hub.ru/https://doi.org/10.1080/15507394.2004.10012342
Sibley, C. G., Osborne, D., & Duckitt, J. (2012). Personality and political orientation: Meta-analysis and test of a Threat-Constraint Model. Journal of Research in Personality, 46(6), 664–677. Retrieved from https://sci-hub.ru/https://doi.org/10.1016/j.jrp.2012.08.002
Eagan, K. (2016). The American freshman: Fifty-year trends, 1966-2015. Higher Education Research Institute, Graduate School of Education & Information Studies, University of California, Los Angeles. Retrieved from https://www.heri.ucla.edu/monographs/50YearTrendsMonograph2016.pdf
Saad, L. (2023). Democrats' Identification as Liberal Now 54%, a New High. Gallup News. Retrieved from https://news.gallup.com/poll/467888/democrats-identification-liberal-new-high.aspx
Jones, J. M. (2023). Social Conservatism in U.S. Highest in About a Decade. Gallup News. Retrieved from https://news.gallup.com/poll/506765/social-conservatism-highest-decade.aspx
ROBINSON, J. P., & FLEISHMAN, J. A. (1984). Ideological Trends in American Public Opinion. The ANNALS of the American Academy of Political and Social Science, 472(1), 50–60. Retrieved from https://sci-hub.ru/https://doi.org/10.1177/0002716284472001005
Enten, H. (2015). There Are More Liberals, But Not Fewer Conservatives. FiveThirtyEight. Retrieved from https://fivethirtyeight.com/features/there-are-more-liberals-but-not-fewer-conservatives/
Davern, Michael; Bautista, Rene; Freese, Jeremy; Herd, Pamela; and Morgan, Stephen L.; General Social Survey 1972-2024. [Machine-readable data file]. Principal Investigator, Michael Davern; Co-Principal Investigators, Rene Bautista, Jeremy Freese, Pamela Herd, and Stephen L. Morgan. Sponsored by National Science Foundation. NORC ed. Chicago: NORC, 2024: NORC at the University of Chicago [producer and distributor]. Data accessed from the GSS Data Explorer website at https://gssdataexplorer.norc.org/trends?category=Politics&measure=polviews_r
American National Election Studies. 2021. ANES 2020 Time Series Study Full Release [dataset and documentation]. February 10, 2022 version. Retrieved from https://electionstudies.org/data-center/2020-time-series-study/
Woessner, M., & Kelly-Woessner, A. (2009). I Think My Professor is a Democrat: Considering Whether Students Recognize and React to Faculty Politics. PS: Political Science & Politics, 42(02), 343–352. Retrieved from https://sci-hub.ru/https://doi.org/10.1017/S1049096509090453
Mariani, M. D., & Hewitt, G. J. (2008). Indoctrination U.? Faculty ideology and changes in student political orientation. PS: Political Science & Politics, 41(4), 773-783. Retrieved from https://sci-hub.ru/https://doi.org/10.1017/S1049096508081031
Saad, L. (2024). U.S. Women Have Become More Liberal; Men Mostly Stable. Gallup News. Retrieved from https://news.gallup.com/poll/609914/women-become-liberal-men-mostly-stable.aspx
Kerry, N., Al-Shawaf, L., Barbato, M., Batres, C., Blake, K. R., Cha, Y., ... & Murray, D. R. (2022). Experimental and cross-cultural evidence that parenthood and parental care motives increase social conservatism. Proceedings of the Royal Society B, 289(1982), 20220978. Retrieved from https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9449478/pdf/rspb.2022.0978.pdf
Angleson, C. (2024). How Heritable Are Political Views? Taking The Twin Literature Seriously. half-baked thoughts. Retrieved from https://werkat.substack.com/p/how-heritable-are-political-views
Viechtbauer, W., & Viechtbauer, M. W. (2015). Package ‘metafor’. The Comprehensive R Archive Network. Package ‘metafor’. Retrieved from http://cran.r-project.org/web/packages/metafor/metafor.pdf
Bornmann, L., Mutz, R., & Daniel, H.-D. (2010). A Reliability-Generalization Study of Journal Peer Reviews: A Multilevel Meta-Analysis of Inter-Rater Reliability and Its Determinants. PLoS ONE, 5(12), e14331. Retrieved from https://sci-hub.ru/https://doi.org/10.1371/journal.pone.0014331
Nunnally, J. C., & Bernstein, I. H. (1994). Psychometric Theory Third Edition. McGraw-Hill Inc. ISBN-10:007047849X. Retrieved from http://not-equal.org/content/pdf/misc/Nunnally1994.pdf
Bradley, J. V. (1981). Pernicious publication practices. Bulletin of the Psychonomic Society, 18(1), 31–34. Retrieved from https://sci-hub.ru/https://doi.org/10.3758/BF03333562
Emerson, G. B., Warme, W. J., Wolf, F. M., Heckman, J. D., Brand, R. A., & Leopold, S. S. (2010). Testing for the Presence of Positive-Outcome Bias in Peer Review. Archives of Internal Medicine, 170(21). Retrieved from https://sci-hub.ru/https://doi.org/10.1001/archinternmed.2010.406
Fang, F. C., Steen, R. G., & Casadevall, A. (2012). Misconduct accounts for the majority of retracted scientific publications. Proceedings of the National Academy of Sciences, 109(42), 17028–17033. doi:10.1073/pnas.1212247109 Retrieved from https://sci-hub.ru/https://doi.org/10.1073/pnas.1212247109
Steen, R. G. (2010). Retractions in the scientific literature: do authors deliberately commit research fraud? Journal of Medical Ethics, 37(2), 113–117. Retrieved from https://sci-hub.ru/https://doi.org/10.1136/jme.2010.038125
Fang, F. C., & Casadevall, A. (2011). Retracted Science and the Retraction Index. Infection and Immunity, 79(10), 3855–3859. Retrieved from https://sci-hub.ru/https://doi.org/10.1128/IAI.05661-11
Brembs, B. (2018). Prestigious Science Journals Struggle to Reach Even Average Reliability. Frontiers in Human Neuroscience, 12. Retrieved from https://sci-hub.ru/https://doi.org/10.3389/fnhum.2018.00037
German, K. & Stevens, S.T. (2022). Scholars under fire: 2021
year in review. The Foundation for Individual Rights and Expression. Retrieved from https://www.thefire.org/sites/default/files/2022/03/02150546/Scholars-Under-Fire-2021-year-in-review_Final.pdf
Stevens, S., & Schwictenberg, A. (2020). College Free Speech Rankings: What’s the climate for free speech on America’s college campuses. The Foundation for Individual Rights in Education. Retrieved from https://not-equal.org/content/pdf/misc/Stevens2021.pdf
Stevens, S., & Schwictenberg, A. (2021). College Free Speech Rankings: What’s the climate for free speech on America’s college campuses. The Foundation for Individual Rights in Education. Available online at: https://www.thefire.org/sites/default/files/2021/09/24110044/2021-CFSR-Report-v2.pdf
Pesta, B., Kirkegaard, E. O. W., & Bronski, J. (2024). Is Research on the Genetics of Race / IQ Gaps “Mythically Taboo?”, OpenPsych. Retrieved from https://openpsych.net/files/papers/Pesta_2024a.pdf
Bitzan, J. (2023). 2023 American College Student Freedom, Progress And Flourishing Survey. NSDU. Retrieved from https://www.ndsu.edu/fileadmin/challeyinstitute/Research_Briefs/American_College_Student_Freedom_Progress_and_Flourishing_Survey_2023.pdf
Lindqvist, J., & DORNSCHNEIDER‐ELKINK, J. A. (2024). A political Esperanto, or false friends? Left and right in different political contexts. European Journal of Political Research, 63(2), 729-749. Retrieved from https://not-equal.org/content/pdf/misc/Lindqvist2024.pdf
Angleson, C. (2024). “Anti-Racist” = Anti-White. half-baked thoughts. Retrieved from https://werkat.substack.com/p/anti-racist-anti-white
Cory Clark, Bo M Winegard, Dorottya Farkas. (2024). Support for Campus Censorship. Qeios. Retrieved from https://www.qeios.com/read/CMVJP3.2/pdf
Stewart-Williams, S., Thomas, A., Blackburn, J. D., & Chan, C. Y. M. (2019). Reactions to male-favoring vs. female-favoring sex differences: A preregistered experiment. British Journal of Psychology, 112(2). Retrieved from https://sci-hub.ru/https://doi.org/10.1111/bjop.12463
Winegard, B. M. (2018). Equalitarianism: A Source of Liberal Bias (Doctoral dissertation, The Florida State University). Retrieved from https://gwern.net/doc/sociology/2018-winegard.pdf
Jost, J. T., Glaser, J., Kruglanski, A. W., & Sulloway, F. J. (2003). Political Conservatism as Motivated Social Cognition. Psychological Bulletin, 129(3), 339-375. Retrieved from https://gspp.berkeley.edu/assets/uploads/research/pdf/jost.glaser.political-conservatism-as-motivated-social-cog.pdf
Uhlmann, E. L., Pizarro, D. A., Tannenbaum, D., & Ditto, P. H. (2009). The motivated use of moral principles. Judgment and Decision making, 4(6), 479-491. Retrieved from https://www.sas.upenn.edu/~baron/journal/9616/jdm9616.pdf
Tetlock, P. E., Kristel, O. V., Elson, S. B., Green, M. C., & Lerner, J. S. (2000). The psychology of the unthinkable: taboo trade-offs, forbidden base rates, and heretical counterfactuals. Journal of personality and social psychology, 78(5), 853. Retrieved from https://sci-hub.ru/https://doi.org/10.1037/0022-3514.78.5.853
Goldberg, Z. (2022). Explaining Shifts in White Racial Liberalism: The Role of Collective Moral Emotions and Media Effects. Retrieved from https://not-equal.org/content/pdf/misc/Goldberg2022.pdf
Kuhn, P. J., & Osaki, T. T. (2022). When is Discrimination Unfair? National Bureau of Economic Research (No. w30236). Retrieved from https://www.nber.org/system/files/working_papers/w30236/w30236.pdf
Axt, J. R., Ebersole, C. R., & Nosek, B. A. (2016). An unintentional, robust, and replicable pro-Black bias in social judgment. Social Cognition, 34(1), 1-39. Retrieved from https://sci-hub.ru/https://doi.org/10.1521/soco.2016.34.1.1
Kteily, N. S., Rocklage, M. D., McClanahan, K., & Ho, A. K. (2019). Political ideology shapes the amplification of the accomplishments of disadvantaged vs. advantaged group members. Proceedings of the National Academy of Sciences, 116(5), 1559-1568. Retrieved from https://sci-hub.ru/https://doi.org/10.1073/pnas.1818545116
Inbar, Y., & Lammers, J. (2012). Political Diversity in Social and Personality Psychology. Perspectives on Psychological Science, 7(5), 496–503. Retrieved from https://sci-hub.ru/https://doi.org/10.1177/1745691612448792
Kirkegaard, E. (2022). IQ's by university major from SAT's. Just Emil Kirkegaard Things. Retrieved from https://www.emilkirkegaard.com/p/iqs-by-university-degrees-from-sats
Klein, D., & Stern, C. (2004). How Politically Diverse Are the Social Sciences and Humanities? Survey Evidence from Six Fields (No. 53). The Ratio Institute. Retrieved from https://core.ac.uk/download/pdf/7088884.pdf
Chilton, A. S., & Posner, E. A. (2015). An empirical study of political bias in legal scholarship. The Journal of Legal Studies, 44(2), 277-314. Retrieved from https://sci-hub.ru/https://doi.org/10.1086/684302
Acosta, J., & Kemmelmeier, M. (2022). The changing association between political ideology and closed-mindedness: Left and right have become more alike. Journal of Social and Political Psychology, 10(2), 657-675. Retrieved from http://not-equal.org/content/pdf/misc/10.5964.jspp.6751.pdf
Woessner, M., Maranto, R., & Thompson, A. (2019). Is Collegiate Political Correctness Fake News? Relationships between Grades and Ideology. EDRE Working Paper No. 2019-15. Retrieved from https://core.ac.uk/download/pdf/215464412.pdf
Honeycutt, N., & Freberg, L. (2016). The Liberal and Conservative Experience Across Academic Disciplines. Social Psychological and Personality Science, 8(2), 115–123. Retrieved from https://sci-hub.ru/https://doi.org/10.1177/1948550616667617
Peters, U., Honeycutt, N., De Block, A., & Jussim, L. (2020). Ideological diversity, hostility, and discrimination in philosophy. Philosophical Psychology, 33(4), 511-548. Retrieved from https://sci-hub.ru/https://doi.org/10.1080/09515089.2020.1743257
Hanania, R. (2021). Why Is Everything Liberal? Richard Hanania’s Newsletter. Retrieved from https://richardhanania.com/p/why-is-everything-liberal
Dutton, E., & Rayner-Hilles, J. O. A. (2022). The past is a future country: The coming conservative demographic revolution (Vol. 76). Andrews UK Limited. Retrieved from https://not-equal.org/content/pdf/misc/Dutton2022.pdf
Van Ophuysen, S. (2006). Vergleich diagnostischer Entscheidungen von Novizen und Experten am Beispiel der Schullaufbahnempfehlung. Zeitschrift für Entwicklungspsychologie und Pädagogische Psychologie, 38(4), 154-161. Retrieved from https://econtent.hogrefe.com/doi/epdf/10.1026/0049-8637.38.4.154
Nature. (2019). Nature celebrates the one-page wonders too pithy to last. Nature, 568(7753), 433–433. Retrieved from https://www.nature.com/articles/d41586-019-01233-3
Einstein, A. (1921). A Brief Outline of the Development of the Theory of Relativity. Nature, 106(2677), 782–784. Retrieved from https://sci-hub.ru/https://doi.org/10.1038/106782a0
Stapleton, A. (2024). 100 Top Journals In The World: Ranking, High Impact Journals By Impact Factor. Academia Insider. Retrieved from https://academiainsider.com/top-journals-in-the-world/
Rothman, S., Kelly-Woessner, A., & Woessner, M. (2010). The still divided academy: How competing visions of power, politics, and diversity complicate the mission of higher education. Rowman & Littlefield Publishers. Retrieved from https://not-equal.org/content/pdf/misc/Rothman2011.pdf
Woessner, M., & Kelly-Woessner, A. (2020). Why college students drift left: The stability of political identity and relative malleability of issue positions among college students. PS: Political Science & Politics, 53(4), 657-664. Retrieved from https://sci-hub.ru/https://doi.org/10.1017/S1049096520000396
Gross, N., & Simmons, S. (Eds.). (2014). Professors and their politics. JHU Press. Retrieved from https://not-equal.org/content/pdf/misc/Gross2014.pdf

Verbose gobbledygook doesn’t suddenly gain epistemic rigor once you get a couple of your drinking buddies together to put a “peer-reviewed” sticker on it.
King
Why not publishing this as a paper? You should definitely do it.